
The Unix file system is a methodology for logically organizing and storing large quantities of data such that the system is easy to manage. A file can be informally defined as a collection of (typically related) data, which can be logically viewed as a stream of bytes (i.e. characters). A file is the smallest unit of storage in the Unix file system.
By contrast, a file system consists of files, relationships to other files, as well as the attributes of each file. File attributes are information relating to the file, but do not include the data contained within a file. File attributes for a generic operating system might include (but are not limited to):
From the beginners perspective, the Unix file system is essentially composed of files and directories. Directories are special files that may contain other files.
The Unix file system has a hierarchical (or tree-like) structure with its highest level directory called root (denoted by /, pronounced slash). Immediately below the root level directory are several subdirectories, most of which contain system files. Below this can exist system files, application files, and/or user data files. Similar to the concept of the process parent-child relationship, all files on a Unix system are related to one another. That is, files also have a parent-child existence. Thus, all files (except one) share a common parental link, the top-most file (i.e. /) being the exception.
Below is a diagram (slice) of a "typical" Unix file system. As you can see, the top-most directory is / (slash), with the directories directly beneath being system directories. Note that as Unix implementaions and vendors vary, so will this file system hierarchy. However, the organization of most file systems is similar.
While this diagram is not all inclusive, the following system files (i.e. directories) are
present in most Unix filesystems:
How can this be, you ask? Since all data is essentially a stream of bytes, each device can be viewed logically as a file.
All files in the Unix file system can be loosely categorized into 3 types, specifically:
The first type of file listed above is an ordinary file, that is, a file with no "special-ness". Ordinary files are comprised of streams of data (bytes) stored on some physical device. Examples of ordinary files include simple text files, application data files, files containing high-level source code, executable text files, and binary image files. Note that unlike some other OS implementations, files do not have to be binary Images to be executable (more on this to come).
The second type of file listed above is a special file called a directory (please don't call it a folder?). Directory files act as a container for other files, of any category. Thus we can have a directory file contained within a directory file (this is commonly referred to as a subdirectory). Directory files don't contain data in the user sense of data, they merely contain references to the files contained within them.
It is perhaps noteworthy at this point to mention that any "file" that has files directly below (contained within) it in the hierarchy must be a directory, and any "file" that does not have files below it in the hierarchy can be an ordinary file, or a directory, albeit empty.
The third category of file mentioned above is a device file. This is another special file that is used to describe a physical device, such as a printer or a portable drive. This file contains no data whatsoever, it merely maps any data coming its way to the physical device it describes.
1 Device file types typically include: character device files, block device files, Unix domain sockets, named pipes and symbolic links. However, not all of these file types may be present across various Unix implementations.
By rule, Unix file names do not have to have ending extensions (such as .txt or .exe) as do some other operating systems. However, certain applications with which you interact may require extensions, such as Adobe's Acrobat Reader (.pdf) or a web browser (.html). And as always character case matters (don't tell me you have forgotten this already?). Thus the following are all valid Unix file names (note these may be any file type):
My_Stuff a file named My_Stuff my_stuff a different file than above mortgage.c a C language program...can you guess what it does? a.out a C language binary executable .profile ksh default startup file
While file names are certainly important, there is another important related concept, and that is the concept of a file specification1 (or file spec for short). A file spec may simply consist of a file name, or it might also include more information about a file, such as where is resides in the overall file system. There are 2 techniques for describing file specifications, absolute and relative.
With absolute file specifications, the file specification always begins from the root directory, complete and unambiguous. Absolute file specs are sometimes referred to as fully qualified path names2. Thus, absolute file specs always begin with /. For example, the following are all absolute file specs from the diagram above:
/etc/passwd /bin /usr/bin /home/mthomas/bin /home/mthomas/class_stuff/fooNote the the first slash indictes the top of the tree (root), but each succeeding slash in the file spec acts merely as a separator. Also note the files named bin in the file specifications of /bin, /usr/bin, and /home/mthomas/bin are different bin files, due to the differing locations in the file system hierarchy.
With relative file specifications, the file specification always is related to the users current position or location in the file system. Thus, the beginning (left-most part) of a relative file spec describes either:
What this means then is that a relative file specification that is valid from one file system position is probably not valid from another location. Beginning users often ask "How do I know where I am?" The command to use to find this is the pwd (print working directory) command, which will indicate the users current position (in absolute form) in the file system.
As mentioned abpve, part of a relative file specification can be a reference to a parent directory. The way one references a parent (of the current) directory is with the characters .. (pronounced dot-dot). These characters (with no separating spaces) describe the parent directory relative to the current directory, again, one directory level up in the file system. Note that more than one level up (a parents parent, for example) can be referenced with ../.., up two levels in this example.
The following are examples referencing the diagram above:
To identify where we are, we type and the system returns the following:
$ pwd [Enter] /home/mthomas/class_stuff Thus the parent of this directory is: /home/mthomas # in absolute form .. # in relative form Looking at another example: $ pwd [Enter] /home/mthomas Thus the parent of this directory is: /home # in absolute form .. # in relative form And one (note there could be many) child of the /home/mthomas directory is: /home/mthomas/bin # in absolute form bin # in relative formSo you ask "How the heck do we use this?" One uses this to navigate or move about the file system. Moving about the file system is accomplished by using the cd command, which allows a user to change directories. In the simplest usage of this command, entering
$ cd [Enter]will move the user to their "home" or login directory (as specified by the $HOME variable 4). If a user wishes to change to another directory, the user enters
$ cd file_spec [Enter]and assuming file_spec is a valid directory, the users current working directory will now be this directory location. Remember, the file specification can always be a relative or an absolute specification.
As before, we type and the system returns the following:
$ pwd [Enter] /home/mthomas/class_stuff If we wish to change directories to the /home/mthomas/bin directory, we can type $ cd /home/mthomas/bin [Enter] # absolute, will work from anywhere or $ cd .. [Enter] # relative, move up one directory, i.e. to the parent $ cd bin [Enter] # relative, move down to the bin directory or $ cd ../bin [Enter] # relative, both steps in one file spec
Novice users sometimes ask which file specification method should they use, or which one is better. The simple and open ended answer is "it depends." That is it depends upon where one currently is in the file system hierarchy, and what one is trying to do. This also depends upon how long the file specification is, or how easy it is to type, including any special characters, or how familiar one is with the current location in the file system hierarchy, etc.
Take some time to navigate the file system of your Unix implementation and see how it compares to the diagram above.
1 Some might choose to call this a path name or path specifier, but I prefer to call this a file specification since all the individual components are files.
2 Fully qualified path names, also referred to as FQPN, are frequently used by system administrators who are used to working with DNS. More information can be found by searching on fully qualified path names in your favorite search engine.
3 A user can also move to their "home" directory using the command cd ~ (tilde), where the ~ character represents a users "home" directory. If used in this simple way, cd and cd ~ are equivalent. However, much more sophisticated behaviorcan be achieved using the ~ character as described here.

From the above output, we can observe 7 attribute fields listed for each file. From right to left, the attribute fields are:
2 This is the number of characters in the file, not necessarily the size on disk, since files are written to disk in 1024 byte blocks. Note also if the file is a directory, this is the size of the structure needed to manage the directory hierarchy.
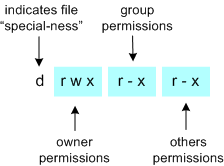
The first (leftmost) character indicates the "type" of the file. Another way to describe this is whether the file has any special attributes associated with it. If it is an ordinary file (i.e. no special attributes), it will have a dash in this first position. If it is a directory file, it will have the letter d in this position. Or, if it is a link to another file it will have the letter l (ell) in this first position. You can see examples of an ordinary file and a directory in the ls -l output above. Other special attributes exist but do not merit discussion here.
The next 9 characters are arranged in 3 groups of 3 characters each; that is 3 characters to describe the permissions for the owner of the file, 3 characters to describe the permissions for the group and 3 characters for all other users permissions. The 3 characters indicate whether the particular user has read (denoted by r), write (denoted by w), or execute (denoted by x) permissions on that particular file. Thus in the diagram above, the owner of the file has all available permissions (indicated by rwx), a user belonging to this group has read and execute (indicated by r-x) permissions, and everyone else also has read and execute permissions. Observe if a user does not have a particular permission, a dash will appear instead of the corresponding letter.
Changing the permission of an existing file is accomplished using the chmod command, that is to change file protection modes. Changing the permission for a file (or files) can only be done by the owner of the file (or the root user). The usage of this command (using octal mode 1) is
chmod ijk file(s)where ijk represent 3 octal numbers (0-7); where i selects the user permissions, j selects the group permissions and k selects the permissions for all others. To disable all (read, write and execute) permissions for any group, you set the respective i, j or k value to 0. To set read permission for any grouping (i.e. user, group or other) you add the value of 4 to the respective i, j, or k value, to set write permission, you add 2 and to set execute permission, you add 1. The values of 4, 2, and 1 are derived from the first three powers of two, i.e. 22, 21, 20 respectively. Thus to set the user permissions to rwx, you set i to 7 (4 for read + 2 for write + 1 for execute), to set the group and other permissions to r-x, you set j to 5 (4 + 1) and likewise for k. The command to select this would then look as follows:
chmod 755 file_spec(s)
To illustrate with another example, if the owner of a file wanted to set read and execute for the user permissions, read only for group permissions and disable all permissions for all others, the command to set this would be
chmod 540 file_spec(s)which would result in protection modes displayed as
-r-xr----- #assuming an ordinary fileWe can see from these two examples that to allow all permissions, you use the maximum value of 7; to prohibit all permissions, you use the minimum value of 0. As a user, you will not have to remember every combination of 4, 2, and 1; typically you will standard combinations such as 755, 644, 700, etc.
The permissions of read, write and execute take on a slightly different meaning with respect to directory files. Thus if a file is a directory:
Where chmod sets permissions on existing files, setting
General syntax is as follows:
umask [-S] [mode]If no -S option or mode is specified, umask reports the current umask mode as octal values. If the -S option is specified and mode omitted, umask reports the umask mode in symbolic mode. For example:
$ umask [Enter] 022 $ umask -S [Enter] u=rwx,g=rx,o=rxAs with chmod, umask uses a single octal digit for each of the owner, group and other fields. If a 3 digit mode value is given (without the -S), the mode value specified is "removed from" 777 (e.g. drwxrwxrwx) for newly created directories and "removed from" 666 (e.g. -rw-rw-rw) for newly created files. Note this is not subtraction 2, the octal values determine what permissions are disabled, as described in the table below:
| Octal digit in umask command |
Permissions disabled during file creation |
| 0 | none, all original permissions will remain |
| 1 | execute permission is disabled |
| 2 | write permission is disabled |
| 3 | write and execute permission are disabled |
| 4 | read permission is disabled |
| 5 | read and execute permissions are disabled |
| 6 | read and write permission are disabled |
| 7 | all permissions are disabled |
Recall that chmod value of 4 for an owner, group or other grants read access. As mentioned, umask is somewhat the opposite of chmod. A umask mode of 4 disables read access for that owner, group or other. The most common setting for umask mode value is 022, set as follows:
$ umask 022[Enter]which leaves all permissions unchanged (from 777 for directories or 666 for ordinary files) for the owner, disables write permission for the group, as well as disables write permission for other (refer to table above). This results in drwxr-xr-x for directories and -rw-r--r-- for ordinary files. Looking at another example:
$ umask 077[Enter]leaves all permissions unchanged for the owner, disables all permissions for the group, as well as disables all permissions for other, resulting in drwx------ for directories and -rw------- for ordinary files.
Note there is no file specification present in the umask command since this command sets the default mode for all newly created files (and directories).
1 There is another way to use the chmod command called symbolic mode which uses symbolic characters instead of numbers. The author prefers octal mode in agreement with [Kernighan & Pike] p. 56, "the octal mode is easier to use." See the chmod man page for information using symbolic mode.
Creating new ordinary files is typically done using application programs. These application programs can be as sophisticated as a large computer-aided design programs (CAD) or as simple as a text editing program. It is dependent upon the application program as to the mechanism for opening and saving files to the Unix file system.
Creating directory files is done with the command mkdir as follows:
mkdir file_specwhere the file_spec is any valid file specification. Keep in mind that to create ordinary or directory files, the user must have write permission for the target location.
Once files are created and saved, users typically find the need to make copies of various files. Files are copied in Unix using the cp command as follows:
cp source_file_spec(s) destination_file_spec(s)where the source and destination file specfication can be any valid file specfication, absolute or relative, as described above. What is important to note here is there must be 2 valid arguments, a source and a destination. Examples of invalid arguments include:
Since the cp command mandates 2 distinct arguments, now is a good time to introduce notation to make things a little simpler. This notation uses a single character named "dot", represented by the . (period) character (not to be confused with "dot-dot" (..) above). The dot character has several uses based upon context (more uses of dot here). In this context, dot will denote your current working directory, in other words, where you are. Thus if you wish to copy a file and have the destination be your current working directory and maintain the same file name, you can simply do:
cp source_file_spec(s) .The dot is the place holder of the 2nd argument and results in all source files being copied to the current working directory with the exact file names. Note without the dot, there is only one argument which will result in a syntax error by the shell.
Moving files is very similar to copying files, the difference being with copy, the source files remain intact while with move, the source files no longer exist in their original location. The command to move files is mv and the syntax is analogous to copy:
mv source_file_spec(s) destination_file_spec(s)
Some examples using the cp command based upon the diagram above given the working directory as follows:
$ pwd [Enter] /home/stu1 $ cp /home/mthomas/class_stuff/foo /home/stu1/foo # pure absolute form $ cp ../mthomas/class_stuff/foo foo # relative form, same file name $ cp ../mthomas/class_stuff/foo new_foo # relative, new file name $ cp ../mthomas/class_stuff/foo /home/stu1 # no file specified, original name assumed $ cp ../mthomas/class_stuff/foo . # destination is current working directory $ cp ../mthomas/class_stuff/foo ~ # destination is "home" directoryUsers can also remove files (including directories) from the file system. The command to delete ordinary files from the file system is rm and its syntax is
rm file_spec(s)Note: if a file has no write permission and the standard input comes from a terminal, most newer versions of rm will prompt the user for whether to remove the file (assuming no -f flag). If any yes (or y or Y) response is given, the file will be removed even though write permission is disabled. This behavior can be circumvented by disabling the write permission on the parent directory. Refer to the rm manual pages for additional details. See code example of this here.
In similar fashion, users can remove directories from the file system using the rmdir command as follows:
rmdir file_spec(s)Keep in mind that both of these commands require valid file specifications as well as sufficient permissions. Occasionly, file names are created with strange characters in them, and require more work to delete. More on this can be found here.
In working with the Unix file system, understanding a few miscellaneous concepts can be helpful. The first of these is the capability to specify multiple files. This is accomplished using something called a metacharacter; that is a character that may have special meaning other than the "literal" meaning of the character. The first of these to discuss is called the wildcard character, represented by the * (asterisk) character.
Using the * character alone represents (matches) all files in the specified location. For example, the command:
$ cp /home/mthomas/class_stuff/* .would copy all files in the class_stuff directory to your current location in the file system tree, keeping all names the same. Note the wildcard character can only be used for the source specification. Similarly, the command:
$ chmod 755 *would change the file protections modes to -rwxr-xr-x for all files in your current directory. You can also use the wildcard character to selectively match the names of files. For example, a* would match (or select) all files that start with the letter a. Looking at an example:
$ ls net* $ chmod 755 net*the first command would list all files starting with the three characters "net", while the second would change the mode (as mentioned above) for all files starting with these three characters. Note when using wildcards as part of a filename, no spaces can be between the literal characters and the wildcard character.
One should be careful using the wildcard character though, as this can have dangerous results. Can you tell what the following command does?
$ rm *
Another topic which can aid in working within the file system is using the copy (cp) command when working with directories. If one wishes to copy all files within a directory to another location, one could simply use the command:
$ cp * destination_file_spec
However, if any of the files to be copied are directories themselves, the cp program will report an error, looking something like:
cp: omitting directory `foo'The workaround to this is to use the -r (recursive copy) option with cp, as follows:
$ cp -r * destination_file_spec
 |
 |
©2025, Mark A. Thomas. All Rights Reserved.