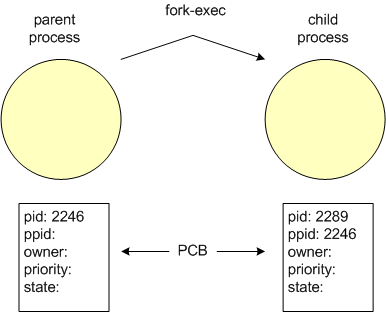
A process can be simply defined as an instance of a running program. It should be understood that a program is part of the file system that resides on a non-volatile media (such as disk), and a process is an entity that is being executed (with at least some portion, i.e. segment/page) in RAM. As one author cleverly stated "...the file system has 'places' and that processes have 'life'." [Christian], p. 471
Since we know that Unix is a multi-user, multi-tasking operating system, we know that multiple processes can be running on a Unix system at the same time. Not only can multiple processes be run at the same time, but on a typical multi-user Unix system, hundreds of processes are running at any given time.
Each time a program is run, a process is created (typically) with the same name as the program itself. So, if the gimp application program is run, a process with the name of gimp is created. Most systems have only one gimp program, but if five users run the gimp program, there will be five processes created named gimp, one for each of the five users. If the processes have the same name, why doesn't the system get the processes confused, you ask? This will be discussed in detail later in this text.
Processes have the concept of a lifetime associated with them. Processes come to life, or are said to be born as a program is loaded and begins execution. Processes remain alive while the program continues execution (processes, however can have different states of life). Processes ceast to exist and are said to die as the running program terminates (either normally or abnormally).
All processes (except the very first one) have a parent which created them. Similarly, when a process is created, it is created as a child process, with the process responsible for its creation being its parent. When a process creates a child process, it is said to have spawned the child. Every process on a Unix system must have a parent (again, except the very first one), since "orphaned" processes are not (normally) allowed. Also, all processes on a Unix system can be linked to the one initial process. As you will see, processes have a similar hierarchical structure to that of the file system.
Each process will have many attributes associated with it. A processes attributes are stored in a structure memory which is called a Process Control Block, or PCB. Each indiviual process will have a PCB associated with it. Some of the attributes relevant to this discussion include:
In the second technique, the parent process is directly overlayed by the "process image" of the newly running process (child). This results in only a single process, since the original parent was overlayed and essentially destroyed. The PID of the new child is the same as the PID of the deceased parent. As above, this process overlaying is accomplished using the exec() system call. Processes will be discussed in greater detail in subsequent sections.
When a Unix machine comes to life, a particular sequence of events takes place. It is of interest to examine this sequence of events as follows:
login:prompt. The getty process then waits (sleeps) for a user to enter their username.
Password:prompt. The login process verifies the username-password pair entered against a corresponding user record in the /etc/passwd file. If the username/password matches the password data in the /etc/passwd file, the startup application (as specified in the /etc/passwd file) is exec'd 1; if the username/password entry does not match, an error is given and access is denied.
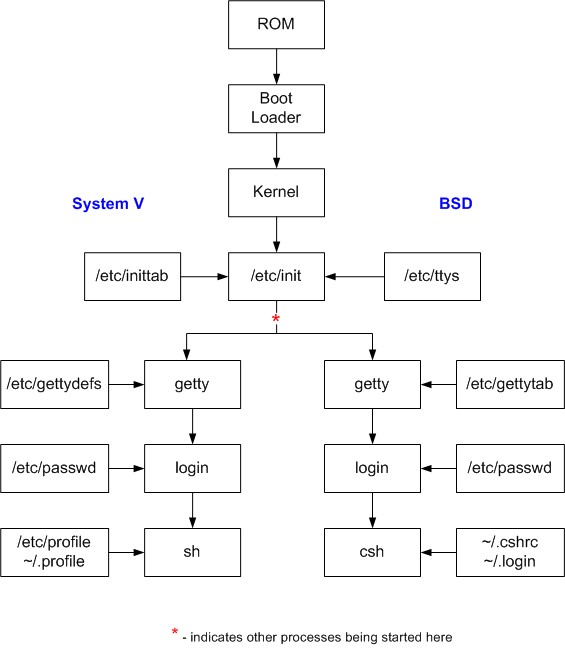
2 The startup application is typically a Unix shell, but it does not have to be, it could be another application program.
3 Numerous files end with the letters "rc" (e.g. .bashrc) on Unix installations. The letters rc are historical in nature and are taken from the words run commands to indicate the intended purpose of the file.
4 Since the original publication of this e-text, the init process has been replaced in some Linux distributions by the systemd process, also having PID 1. This has become somewhat controversial, and has been described as a violation of the Unix philosophy. The following links offer more on the init process and the systemd process systemd process. [Wikipedia contributors]
As mentioned above, after a user enters their username, they are prompted for their password, and their username/password entry is verified against a corresponding record in the /etc/passwd file. Each user with an account on a system has a single line record in the /etc/passwd file. This record is built by system tools when an administrator creates a user account. This might be a little hard to believe, but the /etc/passwd file can be viewed by all users of a Unix system (feel free to try this on your system).
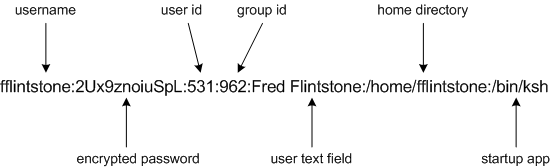
All /etc/passwd records consist of 7 fields, separated by colon (:) delimiters (although not all 7 fields may be populated or used). If fields are un-populated, this may be inconsequential depending upon the field, or it may revert to a default value. The table below describes the 7 fields:
| Field | Description |
|---|---|
| 1 | the user's login username |
| 2 | represents the random-length encryped password (if not an x); many modern versions of Unix use shadow passwords, in which this field will contain an x. |
| 3 | the user's user id (uid) |
| 4 | the user's group id (gid) |
| 5 | contains textual information about the user, such as the user's name, or the department in which they work (data optional) 1 |
| 6 | the user's login directory |
| 7 | the user's startup application |
1 Historically this is referred to as the GECOS field. It originally contained the following information about the user: full name, office number and building, office phone extension and home phone number. This information was required to transfer batch jobs from Unix systems at Bell Labs to large mainframe computers running GECOS. [Nemeth], p. 80
A sample record from the /etc/passwd file may look as follows:
So what is this shell thing, you ask? Simply, the Unix shell is a program that interprets and processes the commands the user types at the keyboard, i.e. the command line interface (CLI). When you type a command and press the Enter key, the shell "interprets" the command, translating and substituting as necessary, then locating, loading and starting the associated program (assuming it is found and displaying errors if it is not). The shell is not the only user interface since several Graphical UI programs are available. However, the shell is indispensible when interacting with the command line driven programs of Unix.
As is common with Unix, there are a variety of shell programs from which one can choose, each one with its own distinctive features. The shell you interact with will generally be selected by the system administrator when your account is created, but can be changed by the user at a later time. Each shell program will also have its own distinctive command line prompt, but this too can be changed by the user.
Some of the more popular (in a historic sense) include:
| Shell Name | Program Name | Description |
|---|---|---|
| Bourne Shell | sh | the original Unix shell created by Steven Bourne, available on most Unix systems |
| C-Shell | csh | a shell created by Bill Joy at Berkely, designed to provide some C language-like features |
| TC-Shell | tcsh | a public domain available extension of csh which allows for command line editing and filename completion |
| Korn Shell | ksh | a shell created by David Korn from Bell Labs which provides features of csh and tcsh with the programming capability similar to sh |
| Bourne Again Shell | bash | a shell available from GNU which combines all the best features from sh, csh and the ksh |
It is important to keep in mind that the shell program, once started (now a process), remains alive for the length of your login session (unless somehow manually terminated). All commands entered at the command line are input arguments to the shell process.
How does the shell interpret and execute a command, you ask? Simply, the normal sequence of steps is as follows:
dir_spec1:dir_spec2:dir_spec3:dir_spec4When the shell searches for a program, it searches each directory specification in order; if it finds the program in a directory, the shell quits looking; otherwise it continues to the next directory specication. More on this later in the text.
 |
 |
©2024, Mark A. Thomas. All Rights Reserved.