While similar to other programming language variables, variables in Unix do have some different characteristics, such as:
variable=valuewhere the value on the right of the = operator is assigned to the variable on the left of the = operator. Note variable assignment always works from right to left. Also pay close attention to the format of the assignment operator where there can be NO spaces on either side of the equal sign (except within the C shell). Including spaces before or after the assignment operator will result in errors.
When naming variables, the rules and conventions are as follows; all variables must begin with a letter (or an underscore), followed by zero or more alpha-numeric chars or underscores. While there is a maximum length, it is quite large and should not be a limiting factor. By convention, variable names are typically typed as uppercase (which helps distinguish them from shell commands). Also by good programming convention, varible names should be descriptive as to what their purpose is. For example, if you are going to use a variable to set a functions return value to zero (as a character), you would do the following:
$ RETVAL=0 [Enter]When accessing the data stored within a variable, you must prefix the variable name with a dollar sign ($). As the shell interprets a variable name following the $, it substitutes the value of the variable at that point. The echo command is typically used to display the value of a single variable, for example if the user types:
$ echo $RETVAL [Enter]the variables value of 0 is displayed. Note that if the $ prefix is omitted, the shell will gladly display exactly what the user has told it to display (the string "RETVAL"), and will not display an error. For example:
0
$ echo RETVAL [Enter]Differing from other languages, variables do not cause errors if they are accessed when they are undefined, or have no value. For example:
RETVAL
$ echo $RET_VAL [Enter] $will merely return a blank line.
You can set variables to the values of directory locations, e.g.
$ MY_BIN=/home/mthomas/bin [Enter]You then have the capability to do things like (assuming the directory location is valid):
$ cd $MY_BIN [Enter] $ pwd [Enter] /home/mthomas/binYou can add to the value of an existing variable such as:
$ MY_BIN=$MY_BIN/new_bin [Enter]Note that if the user wishes to set the variable to a NULL or empty string, this can be done a couple of ways as follows:
RETVAL= RETVAL="" RETVAL=''One important note here is the user can also remove the existance of an environment variable with the unset command. The unset command is substantially different than setting a variables value to NULL, and can have drastic effects (more on this later). To unset a variable, you use the unset command as follows:
unset VARIABLE_NAMENote you do not use the $ when unsetting a variable since you wish to unset the variable, not the variables contents (make sure you understand this). Using the $ when unsetting a variable will result in an error.
There is also an alternate notation for referring to and working with variables. This notation's syntax is ${VAR} rather than $VAR and is generally referred to as parameter expansion. Imagine you have a filename stored in a variable, and you want to rename the filename and append the number 1 to the filename. You might try something like:
$ mv $FNAME $FNAME1 [Enter]This will not work since the shell will think $FNAME1 is a variable, and since it has no value associated with it, an error will occur. Thus you can make this work using the following command:
$ mv $FNAME ${FNAME}1 [Enter]
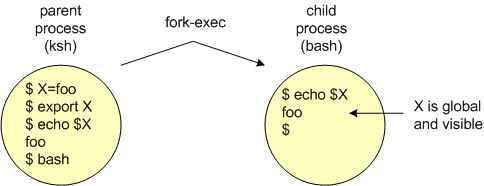
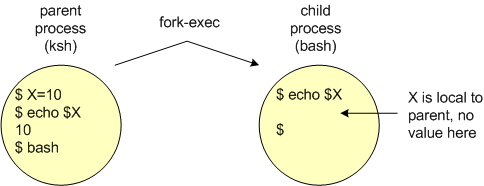
In the example below, the variable X is assigned the (local) value of 10 in the parent (ksh) process environment. When a child process (bash) is created, the value of X (i.e. $X) is not visible in that environment since it is local and visible only in the parent process environment.
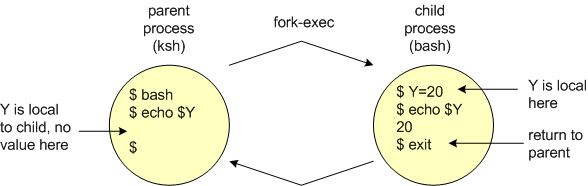
Similarly, in the example below, a child process (bash) is started, a local variable (Y) in the child process is assigned the value of 20, which is then displayed, and control is returned to the parent (via an exit command). When the variable Y is examined in the parent process, it holds no value since the variable Y in the child was local and its value was only visible in the child environment.
If child processes could never see environment variables, variables would have severe limitations and not be all that useful. Thus there is a way to make a shell variable visible to child processes. This is done using the export command as follows:
$ X=10 [Enter] $ export X [Enter]What the export command does is to change the shell variable into a environment variable; that is converts the local variable to a global variable (sort of). This means is the value of the variable X is now visible (persistent) in all child processes created from the parent where it was exported. Note the we export the variable and not the value stored in the variable ($X). Environment variables can be exported at any time including before their use. However it makes sense to export variables near their assignment for program readability (unless this is not desired behavior). A variable need only be exported once; once global, it remains global.You can also do things like the following:
$ X=foo ; Y=bar [Enter] $ export X Y [Enter]The semicolon (;) in the above example allows multiple single commands to be placed on a single line. This is commonly done for readability reasons (more on this later). Also note that some newer shells allow combining of variable assignment and exportation as follows:
$ export X=foo
Examine the behavior of an exported variable in following diagram:
This can be taken a step further; if a variable is exported, it is visible in all child processes (including processes created from child processes, and so on) created from the same parent.
One extremely important point needs to be made here, while exporting a variable makes it global in scope, there is NO mechanism to change the value of a varible in a parent process from a child process.
$ X=Fred ; Y=Barney [Enter] # assign X, Y $ export Y [Enter] # make Y global $ echo "X: $X Y: $Y" [Enter] # examine X, Y X: Fred Y: Barney $ ksh [Enter] # create new child $ echo "X: $X Y: $Y" [Enter] X: Y: Barney # X local so empty $ Y=Betty [Enter] # new value for Y $ echo "X: $X Y: $Y" [Enter] X: Y: Betty $ exit [Enter] # return to parent $ echo "X: $X Y: $Y" [Enter] # original values X: Fred Y: BarneyTo summarize environment variables and child processes:
Each shell variant has a predefined shell file(s) that is automatically executed during the login sequence. The exact file names are specific to each shell flavor, and are listed below (recall these were introduced here). A user can set environment variables in these files and these variables will be defined for every login, appearing as they don't go away. The shell runs the files such that the variables are globally exported. Note, each of these files are hidden files.
| shell | startup file name |
|---|---|
| sh | .profile |
| ksh | .profile |
| csh | .cshrc |
| bash | .bash_profile .bashrc 1 |
An example of this is a modification to the PATH variable that is set for each login. This might look something like:
$ PATH=$PATH:/home/mthomas/binwhich would append the /home/mthomas/bin directory to the end of the existing PATH variable.
1 The bash shell implements two separate startup files (scripts), .bash_profile and .bashrc. The .bash_profile script runs each time a login sequence takes place, with a username and password. The .bashrc script runs each time a new terminal window (xterm) is started, or a new bash process is instantiated.
expr operand1 operator operand2Note the spaces on either side of the operator, these are mandatory and a source of frequent errors. Some of the possible operators include:
addition +Thus you can do arithmetic in the shell such as:
subtraction - multiplication * # must be written as \*, more here) division /
modulus %
$ expr 10 + 2 [Enter] # adding 10 + 2 12There is an alternative way to performing arithmetic calculations available in some of the newer shells (e.g. bash, ksh93). This newer method (sometimes referred to as let) uses the following syntax: $((expression)) . For example:$ I=10 $ expr $I + 2 [Enter] # same using a variable 12
$ expr 10 \* 2 [Enter] # multiplying by 2 20
$ echo $((10 + 2)) [Enter] # with spaces around operator 12$ echo $((10+2)) [Enter] # without spaces 12
$ X=10 [Enter] $ echo $((X + 2)) [Enter] # note no $ on X 12
$ echo $(($X + 2)) [Enter] # with $ on X 12
$ echo $((X * 2)) [Enter] # no \ on * 20
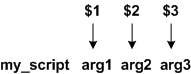
Positional variables (also called positional parameters) are named due to the way they are assigned values, that is based upon their position on the command line. Unlike standard variables, positional variables are only accessible from within a shell script. As mentioned, these variables are named based upon their respective position on the command line. Thus the first argument on the command line (following the program name) is assigned to the variable named 1, the second argument on the command is assigned to the variable named 2, and so on. As with standard variables, access to the values stored within positional variables is achieved using the dollar sign prefix, thus the variables are commonly referred to as $1, $2, etc. In the example below, the name of the shell program is my_script, and the first positional parameter (named 1) has the value within the script of arg1, the second variable the value of arg2, etc.
Thus, if we wish to see the value stored in the first postional parameter, we could do the following from within the my_script program (note that this only works from within the my_script program):
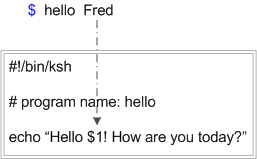
echo $1Positional parameters provide the programmer with a powerful way to "pass data into" a shell program while allowing the data to vary. If we had a shell program named hello that contained the following statement:arg1
echo Hello Fred! How are you today?this would not be very interesting to run, unless perhaps your name was Fred, as it would always acknowledge Fred. However if the program was modified like this:
echo "Hello $1! How are you today?"This would allow us to pass single data values "into" the program via positional parameters as illustrated in the following diagram:
We could then run the program as follows, using varying values to pass into the positional variable $1.
$ hello Fred [Enter] Hello Fred! How are you today? $ hello Barney [Enter] Hello Barney! How are you today?It should be obvious that this would be a much more useful program. Keep in mind that many behaviors of standard variables are also behaviors of positional variables. For example, if you did not assign a value to the first positional variable, you would not get an error, rather behavior as follows:
$ hello [Enter] Hello ! How are you today?Similarly, if there are more command line arguments than positional variables, the extra arguments are simply ignored, for example:
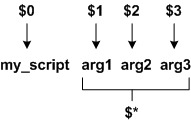
$ hello Fred Barney Dino [Enter] Hello Fred! How are you today?There are also variables referred to as special variables within the various Unix shells. While there are many special variables, I am going to focus on four here. The first three of these are closely related to the positional parameters discussed above, and thus must be referenced from within the program itself. These variables have the names of $*, $# and $0 (note that these special variables are actually named *, #, and 0, but values stored within must be accessed by $*, etc.). The $0 variable is the name of the program/script being executed. The variable $* represents the list of all command line arguments passed into the script. This is effectively a list containing all positional variables. The $# variable is the number of arguments contained in the $* list. Thus the positional variables for any script range from 1 to $#. Referring to the following diagram, we observe:
the variable $0 refers to the name of the script, the positional parameters refer to each individual command line argument, and the variable $* refers to the entire argument list.
We could then modify our hello program to contain the following 2 command statements:
#!/bin/ksh # program name: hello echo "I am program $0 and I have $# argument(s)." echo "Hello $*! How are you today?" |
We could then run the program as follows:
$ hello Fred [Enter] I am program hello and I have 1 argument(s). Hello Fred! How are you today? $ hello Fred Barney Dino [Enter] I am program hello and I have 3 argument(s). Hello Fred Barney Dino! How are you today?Should a user wish, one can also pass NULL or empty values into a shell program as follows:
$ hello Fred "" Dino [Enter] I am program hello and I have 3 argument(s). Hello Fred Dino! How are you today?In this scenario, there are still 3 values being passed into the hello program (as evident with the $# variable), it is simply that the 2nd argument is NULL.
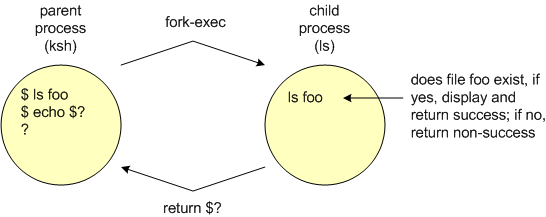
To change directions a bit, the special variable $? is a slightly different creature. Up to this point, I have implied that no data values (e.g. environment variables or changes made to enviroment variables) return from child processes to the parent parent. This is mostly true, except in a single case. The variable $? contains the numeric exit status of the last returning child process. This is the only data value ever returned from a child processto the parent. A value of zero implies success (however that is measured) and a non-zero (not necessarily a one) implies non-success. Note that the status of success and non-success are relative to the commands executed. It is extremely important to understand while this is a binary condition, the values are not zero and one, they are zero and non-zero (frequently it will be one, but not always). Refer to the following diagram:
As mentioned above success and non-success is measured differently for each command. In general, there are three scenarios to illustrate this concept. The first is that of success. An example of this is the attempt to list a file which does exist, and results in that file being listed. The second scenario is that of non-success. An example of this is the attempt to list a file that does not exist. This may not be a catastrophic event, that is if the file does not exist, it may need to be created. However, this is still an non-success by the ls command. The third scenario is that of more severe non-success (i.e. failure), for example mispelling the ls command. In the latter two cases, the $? variable will return a non-success status, but the meaning of each is different. Examine the following examples:
$ ls foo [Enter] # list file foo foo $ echo $? [Enter] # file exists, return success 0 $ ls bar [Enter] # list file bar ls: bar: No such file or directory $ echo $? [Enter] # file does not exist, return non-success 1 $ sl foo [Enter] # typing error ksh: sl: not found $ echo $? [Enter] # erroneous command, return non-success 127Note that the $? variable only returns the status from the last returning child process. If we examine the following:
$ ls bar [Enter] # list file bar ls: bar: No such file or directory $ echo $? [Enter] # file does not exist, return non-success 1 $ echo $? [Enter] 0In the second echo of $?, the status returned was 0 because the previous child process was the previous echo statement, which was indeed successful. Sometimes you will want to store the return status of a process for examination at a later time. In this case, you can simply store the value of the $? variable in a ordinary value as follows:
ERR_STATUS=$?
| Variable | Description |
|---|---|
| $* | all parameters in the parameter list |
| $# | the number of arguments passed into the shell program, in other words, the number of parameters in $* |
| $n | the nthparameter in $* (for 1 ≤ n ≤ $#) |
| $0 | the name of the program being executed, i.e. the 0th parameter |
| $$ | the PID of the program being executed |
| $? | the exit status of the last command executed |
 |
 |
©2024, Mark A. Thomas. All Rights Reserved.