

|
|
|
 I first recorded bird sounds in 1998. I'd stopped for a short walk at a park on my way home from work and happened to be carrying a small tape recorder that I sometimes used for dictation. A Song Sparrow happened to sing from the top of a nearby shrub and I happened to turn on the recorder, capturing 2 renditions of his song. Of course I'd read about such things and so tried playing the songs back to the bird. Immediately 4 or 5 Song Sparrows turned up, started making chipping notes and looked very upset and agressive. I'd read about that too, but hadn't understood how very important singing and songs were to many birds until that day.
I first recorded bird sounds in 1998. I'd stopped for a short walk at a park on my way home from work and happened to be carrying a small tape recorder that I sometimes used for dictation. A Song Sparrow happened to sing from the top of a nearby shrub and I happened to turn on the recorder, capturing 2 renditions of his song. Of course I'd read about such things and so tried playing the songs back to the bird. Immediately 4 or 5 Song Sparrows turned up, started making chipping notes and looked very upset and agressive. I'd read about that too, but hadn't understood how very important singing and songs were to many birds until that day.
It wasn't long before I discovered I could connect the tape recorder to a PC (headphone out to mic in) and use the computer's sound card to digitize recordings as I played them back on the tape recorder. Even at that time there was free software available to edit audio files and even to visualize sounds by generating sonograms.
Imagine my surprise when, having returned several times to visit and record the Song Sparrows at the park, I discovered that I'd been lazy in my listenting and hadn't paid enough attention through all the years I'd been birding. The sparrows in the park were singing upwards of 12 completley different songs! What I'd learned to ``identify'' as a Song Sparrow song was some collection of attributes common to most or their songs. And I could use a cheap recorder and free software to distinguish their songs. That spring and summer I carried the tape recorder whenever I went birding. I read lots of books from the library. I spent a zillion hours writing my own sound editing and sonogram programs. Those were fun time times and my simple equipment was plenty good to let me discover many things about common birds that I'd never even suspected before.
That fall I happened on a flock of Sandhill Cranes, threw myself down in the weeds, turned on the tape recorder, and got something like 15 minutes of audio as the flock got organized, took off (calling the while) and spiraled to altitude right over me. That was the first recording I made that was valuable to me for sentimental reasons (who doesn't love the sound of Cranes?) and that I listened to and shared with friends because it was pretty rather than just something I could measure and draw pictures of.
Since then I've recorded a lot of different birds with the aim of understanding their singing and of enjoying the sounds they make. Nature recordist that I met via email and 'phone --- even the big name pros --- have invariably been generous with their advice and helped me improve my technique.
I enjoy the whole process so much --- I often claim it is the only thing I'll get up before sunrise or stay out until nearly dawn to do --- that I resolved to share some of the fun.
This is short account of what I've learned about Cardinal songs. While I do go into details about sound related projects (e.g. computer recognition of songs) and studies addressing particular hypotheses about Cardinal singing behavior, my main purposes are to (a) provide lots of examples of Cardinal songs and (b) idicate a varieties ways most anyone with a curiosity on bird song can have fun asking and answering questions about it.
This document is currently incomplete and, indeed, will probably never be complete. I've posted it as it is in furtherance of goal (a) above. I don't need to know everything about the songs to at least share them with people.
In Cincinnati, where I live, Northern Cardinals (Cardinals, a.k.a NoCa) start to sing in earnest each year around the end of February or beginning of March. Even if the weather is especially cold and the arrival of spring delayed by masses of arctic air, the increasing length of the days triggers hormonal changes in the birds and a behavioral consequence of these changes is that they --- especially the males --- perch in conspicuous locations such as tree tops or the tips of branches and sing loud songs typical of the species. While the exact nature of the song changes from one bird to the next, all Cardinals seem to recognize all the songs given by their neighbors as being Cardinal songs. Humans who've paid a bit of attention to birds in the eastern U.S. also recognize most Cardinal songs.
Among the singing birds (passerines, including the Cardinal) songs are believed to serve two main purposes: they have roles in establishing breeding territories and in attracting mates. So the lengthening days and the onset of singing behavior marks the start of the Cardinal's breeding season. Within a matter of weeks or a month territories will be established, mates attracted, nests built, and eggs laid. Singing continues into July, well after young of the year have left the nest. It is primarily during this period that new Cardinals, as nestlings and newly fledged young, learn how to sing from hearing the songs of the adults around them.
It is this social transmission of song and its consequences that makes the singing of Cardinals so fascinating to me. A slow spatial diffusion of song types occurs due to imperfect learing of songs and this opperates in conjunction with a more sporadic but potentially faster dispersal of songs associated with the movement of young birds away from their natal territory. These two processes result in the kinds and distribution of the Cardinal songs we here around us each day.
Cardinals are easy to study around Cincinnati. They are permanent residents. They're abundant, reaching (according to some Christmas Bird Counts) their continent-wide highest density around southern Ohio. They're easy to spot and follow (the males at least). They are very loud. They were the obvious choice for a first species for me to spend time investigating. Song Sparrows would have been anpther possibility, but there's many more Cardinals that Song Sparrows near our house.
Here I present a batch of examples of Cardinal songs from a number of different locations and report on some observations about their singing behavior. In an attempt to be useful I've included some discussion of my methods and other information that might encourage and support others in making similar investigations. These remarks are far from systematic but fortunately there several several excellent, comprehensive resources about nature recording on the WEB.
Songs are the Cardinal's most conspicuous vocalizations and are distinguished from other sounds, that people refer to as “notes”, “calls”, and “chips”, by their complex structure, the volume at which they are delivered, and the fact that they are given primarily by males. Songs serve the purpose of advertisement; they're used to declare and defend a breeding territory and to attract mates. In contrast, other sounds seem to serve a number of different purposes of more covert communications such as maintaining contact with mates and warning of the presence of preditors. Further, songs are typically delivered while perched, often in a consicuous locations, while other vocalizations are often given from the ground, while hidden in foliage, and while feeding. As I've mentioned, singing is very important to Cardinals. At the height of the season I've clocked birds that spent 30% of their entire day singing.
Here's a 40 second recording from 18 March 2007. It is from the middle of a longer recording of a male NoCa singing.
You can click on the audio control to play the recording and you can click on and then drag the sonogram to view the rest of it. On most browsers the audio controls will show the time since the start of the recording and this can help you view the corresponding parts of the sonogram since it has seconds marked off along the bottom of the image.

In this recording you can hear and see two repetitions of one song type, a part of another song type, and then two repetitions of this second type of song. These repetitions of each type illustrate the fact that the variabilty among repetitions of a single type of song are minor compared to the differences between songs of different types.
These two song types illustrate features common to most Cardinal songs. Each is made up of a repetition of a particular element, followed by a repetition of another element. Usually there are just 1, 2, or 3 different elements that occur in a song. We recognize these elements, again, because they are the unit of repetition. The different kinds of elements in a song usually appear in a fixed order.
As illustrated by this example, each Cardinal can sing several different kinds of songs. They are described as singing with eventual variation which means that, in a bout of singing, one song type is delivered multiple times and then the singer switches to another type of song. And so on. The collection of all the different kinds of songs that a single bird sings is his repertoire.
To further illustrate the songs Cardinals sing, here is a selection of recordings from one location "Tanglewood" (our yard in College Hill). Each type of song is illustrated with two or three audio clips and corresponding sonograms. The examples illustrating each type of song are either from two different individuals or were recorded several years apart and so most likely from two different individuals. The names given to the song types are arbitrary and were applied in the order with which the songs were first enountered.
I've included song types here that were observed in at least 2 different years that were at least 3 years apart. With two exceptions (song types 9 and 12) each song type was recorded in the yard every year from 1999 to 2017. I've left out songs that occurred in only one year; presumably they were the were due to a dispering birds attempting to immigrate to the area and either moving on or dieing. A reasonable guess is that these one-time songs can be heard at locations not far from Tanglewood at a site where they are endemic. I'd like to go looking for them some day but people don't generally take kindly to strangers carrying funny looking equipment slinking through their neighbood in the predawn.
Type 1 | ||
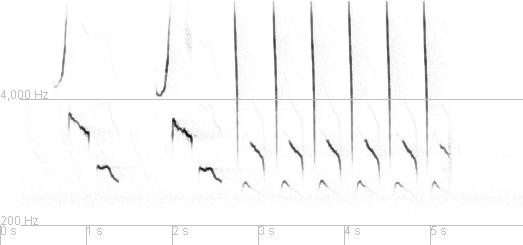 March 2004
March 2004
|
 March 2005
March 2005
|
.jpg) March 2012
March 2012
|
Type 2 | ||
.jpg) March 2011
March 2011
|
.jpg) March 2015
March 2015
|
.jpg) March 2003
March 2003
|
Type 3 | ||
.jpg) March 2010
March 2010
|
.jpg) April 2013
April 2013
|
 March 2005
March 2005
|
Type 4 | ||
.jpg) March 2005
March 2005
|
.jpg) March 2010
March 2010
|
.jpg) March 2015
March 2015
|
Type 5 | ||
.jpg)
|
|
.jpg)
|
Type 6 | ||
 March 2005
March 2005
|
.jpg) Feburary 2011
Feburary 2011
|
.jpg) March 2015
March 2015
|
Type 7 | ||
.jpg)
|

|
.jpg)
|
| Type 8 | ||
 February 2005
February 2005
|
.jpg) March 2012
March 2012
|
.jpg) March 2016
March 2016
|
| Type 9 | ||
.jpg) April 2015
April 2015
|
.jpg) March 2013
March 2013
|
.jpg) March 2007
March 2007
|
| Type 11 | ||
.jpg) March 2013
March 2013
|
.jpg) March 2011
March 2011
|
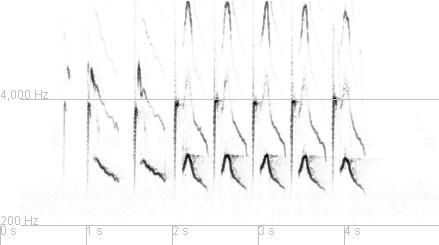 March 2004
March 2004
|
| Type 12 | ||
.jpg) March 2013
March 2013
|
.jpg) February 2010
February 2010
|
It is worth noting several things that are suggested by this overview of the NoCa songs from Tanglewood. The first is that, at a given location, once can expect to hear about 10 different songs. The second is that the collections of songs heard at a given location doesn't change much over time, even on the scale of a decade or two. The third is that you probably "sort of" recognize these songs, some of them at least, but they are not exactly the songs you hear at other locations.
Certainly this one selection of recordings from one location doesn't prove any of these contentions. That requires considerably more evidence: more than any reasonable person would want to see in detail. The quick version is that I've made similar studies at other locations (still in the Cincinnati area) in which I record songs on repeated visits over multile years. These include 2 sites in Cincinnati's Mount Airy Park, one site in Harbin Park in Bulter County, and (with less effort and coverage) 2 sites in Hamilton County's Miami Whitwater Park and one in Butler County's Pater Wildlife Area. The bottom line is that the pattern from Tanglewood seems to hold. One can quickly find 5 or so songs at a site. With multiple visits, say 4 or 5 over March-April, one finds at least 9 or 10 songs. The song types at a site don't change much from year to year. And, the songs at one site aren't exactly the same as at another site.
Some questions:
Here's a selection of songs from Mt Aity Arboretum. A number of them are similar to songs from Tanglewood and are assigned names accordingly.
MtA-1 | |
.jpg) March 2010
March 2010
| |
MtA-2 | |
.jpg) March 2010
March 2010
| .jpg) March 2013
March 2013
|
MtA-4 | |
.jpg) March 2010
March 2010
| .jpg) March 2013
March 2013
|
MtA-6 | |
.jpg) March 2010
March 2010
| .jpg)
|
MtA-7 | |
.jpg) March 2013
March 2013
| .jpg)
|
MtA-11 | |
.jpg) March 2010
March 2010
| .jpg)
|
.jpg) March 2010
March 2010
|
.jpg) May 2016
May 2016
|
.jpg) March 2010
March 2010
| .jpg) March 2013
March 2013
|
.jpg) March 2014
March 2014
| .jpg) March 2013
March 2013
|
.jpg) March 2013
March 2013
| |
This section will present songs from along a transect connecting Tanglewood to Mount Airy. There are several examples of "intermediate" song types (type 2 songs for example) and other examples where there's a sharp transition from one type to another (type 4, where the introductory elements switch from Tanglewood to Mt Airy type abruptly along the transect about where it crosses Kirby Ave.)
The kinds of variation we see over time or between nearby locations include modification/substitution of one of the elements of a song.
Here's a selection of Cardinal songs from other locations near Cincinnati: Harbin Park in Butler County, Pater Wildlife Area in Butler County, and Miami Whitewater Forest Park in western Hamilton County.
Still need to add Spring Grove 2017, Richardson 2015, Northside along with a map showing the locations
Still need to add selections of songs from Adams County, Ohio, Northern Florida, Nebraska, Massachusetts. Perhaps this is getting out of hand and some of this "diversity of songs" material should be put in a separate file and just linked here?
This section will eventually present a are a few recordings from Tanglewood during the period 1999-2017. They indicate that several of the song types persisted at that location during the entire time. I imagine that the life expectancy of a NoCa is probably considerably less than 5 or 6 years, so the songs were given by different birds. Only minor changes in each song type can be seen.
>Deciding on what is a song --- discussed below but it seems reasonable to proceed informally, lets us ask how many different song types there are. As we inspect ever larger areas we expect to detect more song types. On the other hand, there's a remarkable number of types that appear to occurr most every place. And, it turns out, there are certainl song elements that appear to be common across the eastern half of contient. It could be that there are a fixed number of types of song elements --- maybe on the order of 100 or so --- and all songs types are made up of combinations of these elements. Or it could be that, gradually, elements evolve resulting in new, distinguishable, elements, and therefore totally new song types.
My current thinking is that I consider two songs to be of the same type if it is plausible to me that they were both derived from (descended from) a particular song; that all the differences can be accounted for by individual variations in singing ability and the accumulation of alterations resulting from less than perfect learning of songs by young birds.
A more useful definition would be phrased in terms of the effects that hearing a song has on birds, or the physiology involved with the production of the song, or some other measurable traits. Those traits seem to require experiment, not just observation so I've avoided using such a definition.
A statistical analysis of songs, using multivariate methods of clustering, can permit a reasonable, if perhaps biologically arbitrary, delineation of song types. If these methods repeatedly classify songs as humans do, we might rely on them for a function definition of song times and even automatic identification of the types. I've pursued this line of inquiry ( the song probes, library module, and cor-net clustering procedure described below) and the good news is that, at least on the scale of Cincinnati, the results of the statistical modeling agree pretty well with human perceptions of song types.
How are the songs at a given location distributed among the birds that live there? It might be that each bird only has a couple songs and that one or a few of the songs are shared with others that live nearby. At the other end of the song sharing spectrum, it could be that almost all the birds sing almost all the songs from the location. Of course it is alsp possible that some birds have lots of songs and others only a few. With Cardinals I suspect that the situation is that nost birds sing most of the songs. I outline some evidence supporting this suspicion here. Before worrying about the details of sharing songs it helps to resolve the question of individual repertoire: how many different songs does a given bird sing?
The basic idea I've used for estimating an individual's repertoire is to make recordings of the singer until no new songs are detected. Since I don't band or mark the birds there's a bit of a problem with knowing that I'm always recording the same birds --- that all the songs can be attributed to a particular individual. I've taken several approaches to addressing this problem. There's a trade-off between ease of collecting lots of data and the certainty that all the songs are from the same bird.
The direct approach is to record as much song as possible while keeping the individual in sight. The estimate this method provides is very unlikely to attribute songs to the singer incorrectly but might well not samle the bird's entire repertoire.
Here's an uniterupted ( 0:10:25 in duration) recording of a single bird singing from a single perch at Tanglewood. There are 6 different song times that appear here.
The sonogram of the entire recording has been divided into segments that are 2 minutes long and then stacked one on top of the next in the following scrollable image.






And this table identifies the type of songs that appear, along with their location in the recording. Times are in seconds.
| 0.855812 | 6.275956 | type 4 |
| 11.142338 | 13.407723 | type 9 |
| 14.850857 | 18.492254 | type 4 |
| 21.076471 | 27.167840 | type 4 |
| 29.382883 | 31.530803 | type 8 |
| 33.561260 | 38.998184 | type 4 |
| 40.894395 | 45.962145 | type 4 |
| 48.328214 | 53.161035 | type 4 |
| 60.276022 | 79.489843 | type 8 |
| 89.423976 | 93.552011 | type 4 |
| 106.254948 | 109.074094 | type 9 |
| 109.292242 | 113.067883 | type 4 |
| 115.064778 | 119.880819 | type 9 |
| 123.723583 | 145.068544 | type 4 |
| 147.585639 | 151.747235 | type 9 |
| 152.653389 | 164.617978 | type 4 |
| 186.583822 | 206.351404 | type 8 |
| 208.063029 | 211.939354 | type 4 |
| 213.617417 | 229.391209 | type 8 |
| 232.025768 | 236.321609 | type 9 |
| 237.261324 | 239.493148 | type 4 |
| 240.734915 | 243.738648 | type 9 |
| 244.661582 | 257.532325 | type 4 |
| 270.721900 | 275.739309 | type 6 |
| 277.400591 | 331.971199 | type 5 |
| 336.485188 | 384.846963 | type 6 |
| 402.298818 | 406.040899 | type 11 |
| 406.695343 | 412.199390 | type 6 |
| 419.750673 | 422.133523 | type 11 |
| 425.103694 | 428.896116 | type 6 |
| 431.513895 | 435.037827 | type 11 |
| 452.842075 | 460.393359 | type 5 |
| 469.689827 | 491.454304 | type 5 |
| 524.478584 | 529.143599 | type 11 |
| 531.576790 | 614.892617 | type 5 |
Shortly after this recording was made the bird moved to an adjacent treetop and sang non-stop for another 8 minutes, including 2 song types that don't appear here. Because the bird was observed without interruption we know these songs came from a single bird and can conclude that his repertoire contained at least 8 different songs. This is the next to the largest individual repertoire size for NoCa that I've detertmined by this method at Tanglewood. The largest is 9 song types. Over the years other applications of this method at Tanglewood have resulted in estimates of at least 6 and 7 songs.
Another approach is based on the fact that sometimes a bird has a song that is highly distinctive with some attribute that is sufficiently strange that it is implausible that any other bird in the area would share it. One can then record bouts of many singers and attribute to this bird's repertoire all other song types that occur in any bout containing the distinctive song. An analagous approach using visual cues would estimate the repertoire of a bird with a distinctive feature such as a discolored, white, unmoulted, missing, bent, or broken feather.
For example, here is a Type 2 (Tanglewood) song sung by a bird through much of
February and March 2005. While clearly Type 2 (and often sung at the
same time that other Cardinals were singing Type 2 songs) this
version is distinctive because of the nature of its last few
elements.

Below are songs that were sung at Tanglewood over the course of two days in the spring of 2005. They were all sung from the same perch as the distinctive song above and were all sung in conjunction (appear in a continuous recording from a single bird) with a song of this distinctive type.
 Type T3 20 March 2005
Type T3 20 March 2005
|
 Type T3 variant 20 March 2005
Type T3 variant 20 March 2005
|
 Type T11 20 March 2005
Type T11 20 March 2005
|
Type 6 19 March 2005
|
 Type 5 19 March 2005
Type 5 19 March 2005
|
In addition I heard, but did not manage to record, the bird sing a type T1 song.
Singing Types 1,2,3,3var,5,6,and 11 gives this bird a repertoire of at least 7 song types. This is the largest repertoire I've observed for a Northern Cardinal by sampling songs from a distinctive individual.
Since birds establish breeding territories and typically repeatedly sing songs from a small number of perches one may estimate the locations of territories (either by a systematic mapping procedure such as that used in breeding bird surveys) or by more informal procedures, and then attribute to the repertoire of a single male all the song types recorded from perches in his territory, in the core of his territory, or given from one or more of the most used perches.
Of course these less stringent methods can no longer be claimed to produce a strict lower bound on repertoire size since we might be attributing songs from one bird to the repertoire of another. But they provide an improved chance (without too much work) of detecting most or all of the repertoire. The good news is that each of these methods, with enough effort, almost always produces about the same estimate of a bird's repertoire.
My main conclusions about individual repertoires is that most birds that establish a territory at Tanglewood have a repertoire of up to 8 songs and that most have a repertoire of at least 7 songs.
I suspect that the repertoires of all the males establishing territories at Tanglewood is 9 or 10 songs and that they each sing the full complement of songs to be heard at the site. In part this is based on observations, described below, of a behavior called song switching in which, in the middle of a bout, a bird will switch to singing a song type that can be heard from an adjacent neighbor singing at the same time. Being able to switch to match a neighbor's song requires sharing almost all of the neighbor's repertoire.
There are several possible consequences of having songs in common. One is simply that it is possible that two birds near each other sing the same song type at the same time. There's pretty good evidence (though the statistics are tricky) that this situation occurs more often than would be expected at random.
Here's a recording of a Cardinal in the middle of a bout. At the start of the clip he is singing a type 6 song and, in the background, you can hear another bird that singing a type 7 song. The background bird is hard to hear because I recorded the main subject with a directional microphone. The signs of the background singer are also faint in the sonogram, so I've added horizontal red markings to it indicate when you can hear the background singer and indicated (with green lines parallel to and just to the left of) elements of the type 7 song.
.jpg)
tag.jpg)
In this recording, after a few renditions of the type 6 song, the main performer switches to singing a type 7 song, the same song type sung currently by a nearby Cardinal that can be heard faintly in the background of this recording.
This is what I mean by song switching. Of course, because they sing with eventual variation, Cardinals usually do switch song times once or more during a bout. What's especially interesting is that often the switch is to a song type that another bird nearby is singing. When that happens the birds end up singing the same song type, sharing it.
I've attempted to quantify song sharing by making long, stereo recordings in which all the singing Cardinals from the area can be heard. My idea was to tabulate instances in which the bouts of two birds could be heard simultaneoulsy and determine the fraction of all these in which the song type was shared. There are lots of problems with this approach not the least of which is that, just because two birds can be heard in a single recording doesn't mean they can hear each other.
Singing the same song as a neightbor is thought to confer some advantages. Once territorial boundaries have been resolved it isn't worth a bird's effort to respond to a neighbor singing from his usual places. So recognizing neighbors' songs could save a lot of stress and effort. There's no reason that one must share the same songs to recognize them, but that it seems with most species where this efect has been documented, that sharing of repertoire is the norm.
Playback experiments have shown there's usually much stronger reactions (aggression) to playback of strange songs than to songs of types that a bird himeself sings. (I didn't do that and don't do playback at all)
>Still, standing around listenting on typical early morning one hears one NoCa start singing intermittently and shortly afteward all the NoCa with hearing sing the same type of song so that for a period one only hears 1 song type even though there may be 3, 4, or more singers. After a pause in song for feeding, song levels pick up again and birds tend to use the same type song as the bird who started the round of singing. Of course things can get confusing (who started the next round? and some birds never stopped singing?) but the net effect is that often one hears just 1 or 2 song types from all the birds at a given time and location. And, the next morning, other types might be the ones that are the most prevalent.
What properties of a song do Cardinals care about? What makes it a Cardinal song from the point of view of the birds?
What are the consequences of the fact that Cardinals learn their songs and don't disperse vary far? Can we obesrve local song traditions?
Are there aspects of Cardinal songs that affected by the environment (such as man-made noise)?
The Plan: study one type of song that occurs at several locations. I started with about 70 type-2 songs from bouts given by at least 17 different birds at 3 locations (Tanglewood, Mt Airy, Pater WLA) all Recorded Feb-April in 2006 or 2007.
A type 2 song is composed of 3 distinct elements (type 1,2,3). Most songs contain all 3 element types and the elements always occur in the same order. The first element type is repeated 1-4 times. Elements type 2 and 3 are repeated many more times , often 10-15 or more. Element type 2 is shorter in duration that element type 3.

The elements are themselves made up made up of sub-elements. I generated sonograms for each of the type 2 songs in each of the bouts and measured the frequency and time coordinates for several landmark points on each of the type 1 and type 2 elements of each of the songs.
 |
For type 1 elements I measured the first and last points on the first, descending, sub-element #1, and then the highest and lowest frequency points of sub-element #2. These landmark points are shown as red plus signs on the sonogram. Measurement resulted in 4 coordinates (t1,f1,t2,f3) for each occurance of a type 1 element in a song. |
 |
I measured the frequency and time of 5 landmark points on each of the element 2 repetitions in each song. Two points were the lowest and highest frequency points on sub-element #1. These were almost always the first and last (in terms of time) time points as well although in some bird's songs the frequency in these sub-elements increased to a maximum and then decreased. I measured 3 landmarks on sub-elements of type 2. These were the highest frequency point, the inflection point where the two descending elements articulate, and then the last, lowest frequency point. Thus, each occurance of a type 2 element in a song resulted in 10 coordinates (t1,f1,...,t5,f5). Again, landmark points are illustrated in the picture to the left. |
The result of these measuremernts was a large dataset! With 5 numbers from each type 2 element, some 15 type 2 elements per song, and often 5 or 10 type 2 songs in a bout, that's a lot of numbers. To simplify the sitution I selected several summary measurements to work with partly with they intent that they represent some aspect of the songs one could hope to hear in the field. These summary statistics were:
I fit a linear, random effects model for three of these summary statistics. Roughly, this amounted to thinking of each measurement X as a constant plus a sum of random numbers:
X= constant+ location + bout + song + residual
The model expresses the summary statistic X as sum of the contributions of the location, which bout the song occured in, and factors affecting each individual song. Plus a random bit, the resdual, that represents everything not accounted for by the other variables.
Rather than being concerned with the value (size, average) of the random contributions of the various factors, the random effects calculation determines how variable (estimates the variance) the random numbers representing the contributions are. The model attempts to take all the variability in the data and assign it to different sources or causes: differences between locations, differences between singers or bouts at a given location, and random variation in a single bird's repeated performances of the song.
The following table summarizes what we might expect the relative sizes of these contributions to variability to look like under different condition. In the second row of the table, where the variation in the repeated songs of an individual singer is high we suspect that the attribute being modeled is not not one that is learned by Cardinals. The third row describes the situation we'd expect if the trait modeled is one that is learned by Cardinals: THere's little variation in repeated performances by an individual (because the trait was learned well) and not much variation among songs heard at a given location (because most of the birds living there learned from similar models) but reasonable amount of variation from one location to another. Finally, in the last row, the situation in which the trait is not learned but determiend by location is sketched.
| Source | different locations | different bouts/singers at a location | songs from same singer |
| not learned? | any | any | high |
| learned, local tradition | high | medium or low | low |
| not learned, determined by location | high | medium or low | high |
The estimated variance contributions of the different factors to three summary measurements (absolute timing, absolute pitch, and rate of change are shown in the table:
| Source | different locations | different bouts/singers at a location | songs from same singer |
| learned, local tradition | high | medium or low | low |
| Absolute timing | 0.02 | 0.007 | 0.002 |
| Rate of change | 28750 | 13750 | 5800 |
| not learned, determined by location | high | medium or low | high |
| Absolute pitch | 341 | 157 | 261 |
The relative sizes of these variance estimates are what we'd expect if absolute timing and rate of change were traits that Cardinals learned while absolute pitch was a trait that was determined by the birds environment.
I think the approach take here has promise. Of course what I report here is just a feasibility study based itself on some random choices (what song type, what locations, what measurements, what summary statistics) and any real study would need to provide for replication of locations and of song types if features common to multiple songs types could be measured.
Female Cardinals also sing.
Song from a female Cardinal at Tanglewood 28 February 2008. A short rendition of a type 5 song followed by introductory notes of a type 6 song. |
.jpg)
|
A female Cardinal form Tanglewood 11 February 2006. First and second elements from a fairly typical type 2 song appear out of order with some element 1's following element 2's. The song ends with ending elements of a type 3 song. |
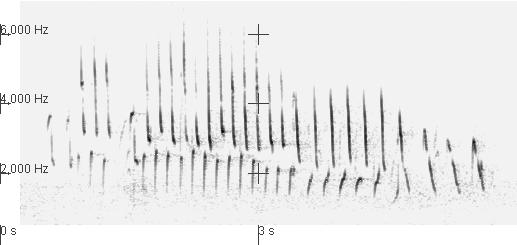
|
Here's a recording of a male and a female Cardinal singing a type 5 song at the same time. April 22, 2017, Tanglewood. The male was dipping his head, spreading his tail.
Here's video of a female Cardinal from Mt Airy Arboretum singing on 25 March 2016. You can hear another Cardinal (it was a male) off camera in the background singing the same type of song.
Recordings were made using an omnidirectional microphone in a plastic, 22 inch parabolic reflector. All the recordings from Tanglewood were made within about 50 yards of our front door; all the recordings from Mt Airy were made within about 300 yards of the parking lot at the Arboretum. Through 2003 I used a cassette tape recorder and digitized the recordings using the sound card in a PC. In starting in 2004 and 2005 I used a Minidisk recorder (and, occasionally, a dat recorder). You'll notice the difference in noise levels in the recordings made with the analog and digital devices. Recordings were transfered to the computer using "line out" on the cassette recorder and "headphones out " on the Minidisk. I used the computer's sound card to digitize the recordings; it was set to take 16 bit samples at 44.1 KHz. Since 2009 I've used digital recorders that allow digital transfer of files to the computer.
Sonograms were generated from the digitized sound files using the Dora2 program or with a stand alone program that implemented the same algorithms used by the Dora2 program.
Dora2 provides the ability to measure and record the time and frequency coordinates of landmark points on a sonogram by reading the coordinates of a mouse controled cursor.
Some tech:





Song probes are an approach to making an objective definition of "song type" and thus for making automatic identification of song types possible. The idea is to take small bits (elements) of real songs and use them as probes by taking an entire song and computing the correlation (or similarity) of the song with each of the probes. Then a multivariate analysis is possible and some clustering or pattern recognition procedure can be used to identify the type of the song.
The "Library" module of Dora2, also available as a stand-alone program called Library computes correlations between sonograms of different sound files. The sonograms of two sounds are generated exactly as in the Sonogram program, including the final scaling that reduces the magnitude of each Fourier coefficient to a number in the range [0,1]. This produces two arrays of numbers, one for each sound. The Library program computes the correlation coefficient between the numbers in the two arrays as well as the correlation between all shifts of one array relative to the other assuming only that they contune to overlap completely. That is, the array from the shorter sound is shifted against the longer, with r computed for each shift.
It reports the maximum of these r's, and these can be used as a measure of the similarity of the sounds.
I generated a collection of probes for songs from Tanglewood by selecting one example of each of the types that I recordered there in 2005. Each sound was split into separate phrases (elements) and one element of each type was selected as a probe. In addition, for elements that are repeated many times, I also created probes that contained two consecutive elements from a repetion. (This provides some measure of the timing or rate at which the elements are repeated). I also created a second set of probes based on 1 recording of each type from Mt Airy in February 2006.
The naming scheme for the probes is, roughly VIa-1 which means that the probe is from as type VI (6) song, that it came from the first (a vs. b vs. c etc) example of such a song, and was an element of the 1 st type. Probes based on songs from Mt Airy have nanes starting with and M.
As a test of these probes, I took samples for the recordings of NoCa from Tanglewood and Mount Airy in 2006 from the month of Februay, selected one full song from each, and used the Library program to find the correlations (similarities) of each of these songs with each of the 2005 Tanglewood probes. The results is an array with 109 rows (one for each 2006 song recorded before 11 March at either Mt Airy, Tanglewood, or on the transect between them) and 69 columns, one for each probe. Using the the values 1-r and a euclidean measure of distance, I processed the array using the hclust routine from R. This routine performs complete hierarchical clustering in an attempt to group rows that are most similar. The results are shown in the figure:

The tips of the resulting tree are labeled with the type I identified for each recording. The prefixes "t","m","tr",and "b" are applied to songs from different locations: Tanglewood, Mt Airy, Tanglewood Ridge, and the powerline cut Between Colerain and Kirby Roads. In addition, several songs that appeared to be of two types were labeled "xn/m" where "n" and "m" are the two types represented.
I consider this clustering pretty good performance. With the exception of tentatively defined "new" song types like MAS,MAZ, MAX from Mt Airy, songs of each "type" I've identified cluster together. This suggests that automatic type identification is possible. The performance of this method could certainly be improved by restricting analysis to songs with only low background noise.
For the most part, all the main types of songs cluster together. Where they don't, I've perhaps made a mistake in assigning a song type.
As would be expected the compound "xn/m" songs cluster either with type "n" or type "m" songs.
Type MAR clusters together inside the type 2 cluster and closest to a type m2 song. This is based partly on the similarity of the 1st elements, and the steep vertical slurs in the 2nd elements. Perhaps MAR is derived from type 2? I recall finding a NoCa at Tangelwood that had no little low frequency hooks on it's type 2-2nd element notes.
One type M7 clusters external to a group cointaining all the other type 7 and type 1 songs. This is an unusual recording with lots of noise and echo as well as conspicuous overtones due to near saturation. It should probably be excluded from analysis based on the poor quality of the recording.
Two MAS and one MAZ cluster with type 8. The MAS,MAX, MAZ complex is still tentatively defined, poorly resolved, and perhaps needs reclassification. Could MAZ and MAS be the same? Look at some older MAZ samples or get more new ones.
Songs a given type (eg types 4,6,7, and 1) are clustered together according to locations, suggesting that there is some significant differentiation between the same type of songs from different locations. Type b7 clusteres with type t6 songs and is quite different from other type 7 songs.
I don't have equipment to measure absolute sound levels, so I rely on making controled sound recordings (always using the same recorder, record level (preamp) setting, microphones, microphone mounts, and wind screens) and digitizing them in exactly the same way (playing the recordings back on the recorder with the same settings, through the same cables, and digitizing the sound using the same soundcard and program settings.) I convinced myself that this procedure works pretty well by generating 1 minute of white noise and then making several versions of this recording with (digital) amplifier settings of 0,-5,-15, and -25 dB. Indoors, in a fairly quiet room, I played each of these recordings back 3 times using the same amplification and recorded the playbacks after readjusting the recorder settings. Each of these recordings I then digitized twice according to my standard procedure. Then I used the SoundMeter program (BlockSize=1024) to measure the log of the average size of the samples in the recordings. A linear mixed effects model (in R using package nlme) showed that the association between the original loudness of the recordings (dB) and the logs of the mean sample sizes was very strong and linear. The variances attributed to replication of the recording and digitization procedures were extremely small. A slight departure from a linear relationship could be seen in the quieter recordings and this was consistent with the explanation that other noise in the room (the computer's fan, for example) were nearly of the same magnitude as the quietest recording.
You don't want all the details. The main conclusion is that the recording and digitization procedure is very reproducable and the scheme implemented in the SoundMeter program works well to generate measurements that reflect the actually sound levels at the time of the recording.
The SoundMeter program reads an audio file (in the .wav format) in blocks of BlockSize (typically 1024, but user-adjustable) samples and finds the mean square of the samples in the block. It then takes the log of this average. The program reports the min, max, mean, and standard deviation of the log's of the means of the squares of the samples.
... that I'm currently interested in.
.jpg)
.jpg)
.jpg)
.jpg)
-1.jpg)
-2.jpg)
-3.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)