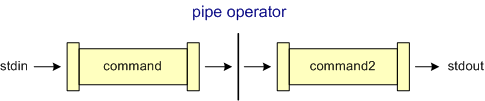
In typical Unix installations, commands are entered at the keyboard and output resulting from these commands is displayed on the computer screen. Thus, input (by default) comes from the terminal and the resulting output (stream) is displayed on (or directed to) the monitor. Commands typically get their input from a source referred to as standard input (stdin) and typically display their output to a destination referred to as standard output (stdout) as pictured below:
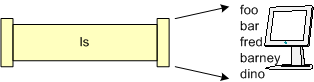
As depicted in the diagram above, input flows (by default) as a stream of bytes from standard input along a channel, is then manipulated (or generated) by the command, and command output is then directed to the standard output. The ls command can then be described as follows; there is really no input (other than the command itself) and the ls command produces output which flows to the destination of stdout (the terminal screen), as below:
The notations of standard input and standard output are actually implemented in Unix as files (as are most things) and referenced by integer file descriptors (or channel descriptors). The file descriptor for standard input is 0 (zero) and the file descriptor for standard output is 1. These are not seen in ordinary use since these are the default values.
The simplest case to demonstrate this is basic output redirection. The output redirection operator is the > (greater than) symbol, and the general syntax looks as follows:
command > output_file_specSpaces around the redirection operator are not mandatory, but do add readability to the command. Thus in our ls example from above, we can observe the following use of output redirection:
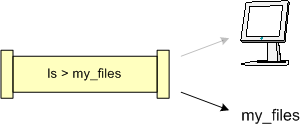
$ ls > my_files [Enter] $Notice there is no output appearing after the command, only the return of the prompt. Why is this, you ask? This is because all output from this command was redirected to the file my_files. Observe in the following diagram, no data goes to the terminal screen, but to the file instead.
Examining the file as follows results in the contents of the my_files being displayed:
$ cat my_files [Enter] fooIn this example, if the file my_files does not exist, the redirection operator causes its creation, and if it does exist, the contents are overwritten. Consider the example below:
bar
fred
barney
dino $
$ echo "Hello World!" > my_files [Enter] $ cat my_files [Enter] Hello World!Notice here that the previous contents of the my_files file are gone, and are replaced with the string "Hello World!"
$ cat my_files [Enter] Hello World! $ cat my_files > my_files [Enter] $ cat my_files [Enter] $
Often we wish to add data to an existing file, so the shell provides us with the capability to append output to files. The append operator is the >>. Thus we can do the following:
$ ls > my_files [Enter] $ echo "Hello World!" >> my_files [Enter] $ cat my_files [Enter] fooThe first output redirection creates the file if it does not exist, or overwrites its contents if it does, and the second redirection appends the string "Hello World!" to the end of the file. When using the append redirection operator, if the file does not exist, >> will cause its creation and append the output (to the empty file).
bar
fred
barney
dino
Hello World!
The ability also exists to redirect the standard input using the input redirection operator, the < (less than) symbol. Note the point of the operator implies the direction. The general syntax of input redirection looks as follows:
command < input_file_specLooking in more detail at this, we will use the wc (word count) command. The wc command counts the number of lines, words and bytes in a file. Thus if we do the following using the file created above, we see:
$ wc my_files [Enter] 6 7 39 my_fileswhere the output indicates 6 lines, 7 words and 39 bytes, followed by the name of the file wc opened.
We can also use wc in conjunction with input redirection as follows:
$ wc < my_files [Enter] 6 7 39Note here that the numeric values are as in the example above, but with input redirection, the file name is not listed. This is because the wc command does not know the name of the file, only that it received a stream of bytes to count.
Someone will certainly ask if input redirection and output redirection can be combined, and the answer is most definitely yes. They can be combined as follows:
$ wc < my_files > wc_output [Enter] $There is no output sent to the terminal screen since all output was sent to the file wc_output. If we then looked at the contents of wc_output, it would contain the same data as above.
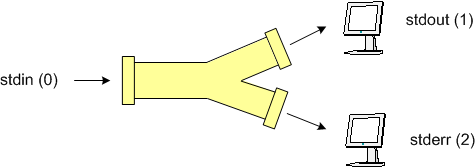
To this point, we have discussed the standard input stream (descriptor 0) and the standard output stream (descriptor 1). There is another output stream called standard error (stderr) which has file descriptor 2. Typically when programs return errors, they return these using the standard error channel. Both stdout and stderr direct output to the terminal by default, so distinguishing between the two may be difficult. However each of these output channels can be redirected independently. Refer to the diagram below:
The standard error redirection operator is similar to the stdout redirection operator and is the 2> (two followed by the greater than, with no spaces) symbol, and the general syntax looks as follows:
command 2> output_file_specThus to show an example, we observe the following:
$ ls foo bar 2> error_file [Enter] foo $ cat error_file [Enter] ls: bar: No such file or directoryNote here that only the standard output appears once the standard error stream is redirected into the file named error_file, and when we display the contents of error_file, it contains what was previously displayed on the termimal. To show another example:
$ ls foo bar > foo_file 2> error_file [Enter] $ $ cat foo_file [Enter] foo $ cat error_file [Enter] ls: bar: No such file or directoryIn this case both stdout and stderr were redirected to file, thus no output was sent to the terminal. The contents of each output file was what was previously displayed on the screen.
Note there are numerous ways to combine input, output and error redirection.
Another relevant topic that merits discussion here is the special file named /dev/null (sometimes referred to as the "bit bucket"). This virtual device discards all data written to it, and returns an End of File (EOF) to any process that reads from it. I informally describe this file as a "garbage can/recycle bin" like thing, except there's no bottom to it. This implies that it can never fill up, and nothing sent to it can ever be retrieved. This file is used in place of an output redirection file specification, when the redirected stream is not desired. For example, if you never care about viewing the standard output, only the standard error channel, you can do the following:
$ ls foo bar > /dev/null [Enter] ls: bar: No such file or directoryIn this case, successful command output will be discarded. The /dev/null file is typically used as an empty destination in such cases where there is a large volume of extraneous output, or cases where errors are handled internally so error messages are not warranted.
One final miscellaneous item is the technique of combining the two output streams into a single file. This is typically done with the 2>&1 command, as follows:
$ command > /dev/null 2>&1 [Enter] $Here the leftmost redirection operator (>) sends stdout to /dev/null and the 2>&1 indicates that channel 2 should be redirected to the same location as channel 1, thus no output is returned to the terminal.
| Redirection Operator | Resulting Operation |
|---|---|
| command > file | stdout written to file, overwriting if file exists |
| command >> file | stdout written to file, appending if file exists |
| command < file | input read from file |
| command 2> file | stderr written to file, overwriting if file exsits |
| command 2>> file | stderr written to file, appending if file exists |
| command > file 2>&1 | stdout written to file, stderr written to same file descriptor |
We can look at an example of pipes using the who and the wc commands. Recall that the who command will list each user logged into a machine, one per line as follows:
$ who [Enter] mthomas pts/2 Oct 1 13:07 fflintstone pts/12 Oct 1 12:07 wflintstone pts/4 Oct 1 13:37 brubble pts/6 Oct 1 13:03Also recall that the wc command counts characters, words and lines. Thus if we connect the standard output from the who command to the standard input of the wc (using the -l (ell) option), we can count the number of users on the system:
$ who | wc -l [Enter] 4In the first part of this example, each of the four lines from the who command will be "piped" into the wc command, where the -l (ell) option will enable the wc command to count the number of lines.
While this example only uses two commands connected through a single pipe operator, many commands can be connected via multiple pipe operators.
Two straightforward commands which are often used as filters are the head and tail commands. When used with file specifications, these two commands display the first or last ten lines (by default) of a file, as follows:
$ head /etc/passwd [Enter] root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin sync:x:5:0:sync:/sbin:/bin/sync shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt mail:x:8:12:mail:/var/spool/mail:/sbin/nologin news:x:9:13:news:/var/spool/news:In the above example, we simply see the first ten lines of the /etc/passwd file. However, if we wanted to see a listing of the ten oldest files in a directory, we could do the following:
$ ls -tl | tail [Enter] -rw-r--r-- 1 root root 315 Jun 24 2001 odbcinst.ini -rw-r--r-- 1 root root 1913 Jun 24 2001 mtools.conf -rw------- 1 root root 114 Jun 13 2001 securetty -rw-r--r-- 1 root root 1229 May 21 2001 bashrc -rw-r--r-- 1 root root 17 Jul 23 2000 host.conf drwxr-xr-x 2 root root 4096 May 15 2000 opt -rw-r--r-- 1 root root 0 Jan 12 2000 exports -rw-r--r-- 1 root root 161 Jan 12 2000 hosts.allow -rw-r--r-- 1 root root 347 Jan 12 2000 hosts.deny -rw-r--r-- 1 root root 0 Jan 12 2000 motdIn this example, the ls command is used with the t and l (ell) options; the t option sorts by modification time and the l (ell) option results in a long listing format. This output is then piped through the tail filter, which only displays the last ten lines, that is the ten oldest files.
The cut command provides the capability to vertically slice through each line of a file based upon character or field positions. When used with the -c (to specify character) option as follows:
cut -cstart_pos-end_pos < input_filethe cut command extracts (and keeps) characters in positions start_pos through end_pos (inclusive), discarding the rest of the line. The start_pos and end_pos are integer values ranging between 1 and the length of the line. For example, if we wish to select only the username of each user currently logged into our system, we could do the following:
$ who | cut -c1-12 [Enter] mthomasThis example pipes the output from the who command into the cut command, where the characters one through twelve are cut (and directed to stdout by default) while all other characters on each line are discarded.
fflintstone
wflintstone
brubble
If one wishes to cut from a starting character position to the end of the line, the end position is omitted as follows:
cut -cstart_pos- < input_fileUsers can also cut based upon "fields" of data by using the -f and (perhaps) the -d options. Refer to man pages for additional details.
The translate command provides the ability to translate characters coming from the standard input and directed to the standard output. General syntax for this command is:
tr set1 set2 < stdinwhere each individual character in set1 is translated to their matching positional character in set2. A common usage of the translate filter is translating a string of characters to upper (or lower) case. Examine the following example:
$ who | cut -c1-12 | tr '[a-z]' '[A-Z]' [Enter] MTHOMASIn this extension of an earlier example, the who command is piped into cut, where the first 12 characters are cut from each line. These twelve characters are then piped into the translate command where each lower case character is translated to their matching upper case counterpart. Unless redirection occurs, output is written by default to standard output.
FFLINTSTONE
WFLINTSTONE
BRUBBLE
The sort command behaves exactly as one might expect, that is, it sorts data directed to it. Thus we can modify our example from above as follows:
$ who | cut -c1-12 | tr '[a-z]' '[A-Z]' | sort [Enter] BRUBBLEThe sort command has options to sort in reverse order, ignore case when sorting, sort based upon multiple keys and a plethora of other options. A related filter, useful when combined with sort is the uniq filter.
FFLINTSTONE
MTHOMAS
WFLINTSTONE
Another filter essential to manipulating strings is the stream editor program, sed. Perhaps the most common use of sed is to substitute one string (i.e. regular expression) with another string. Generic syntax for string/pattern substitution is:
sed 's/original_string/new_string/' < input_file > output_file
Note when using sed as above, the input redirection operator (<) may or may not be used, behavior in either case will be the same. Additionally, if no output redirection is specified, the output is directed by default to stdout.
A simple example of this is to substitute every occurance of the string UNIX with the string Unix as follows (refer to preface for an explanation of why):
$ sed 's/UNIX/Unix/' input_file > output_file [Enter]
The s directive to sed implies to substitute an occurance of the first string (UNIX) with the second string (Unix); receiving input from the file input_file and directing output to the file output_file. Note that sed never makes changes to the input file. If the input file is to be permanently changed, one should: 1) save the output from sed to a temporary file, 2) verify the temporary file has been modified as desired, and 3) replace the original file with the temporary file (using mv), demonstrated as follows:
$ sed 's/UNIX/Unix/' < input_file > temp_file [Enter] $ cat temp_file [Enter] # verify changes are correct $ mv temp_file input_file [Enter]
In general, the sed command is not intended for the novice. In the above example, results might not be as desired. My use of the phrase an occurance above should have more accurately read the first occurance on a line. To substitute every occurance on a line, the sed global option (g) should be specified as follows:
$ sed 's/UNIX/Unix/g' input_file > output_file [Enter]The description of sed here is not intended to be inclusive or in depth, and is mentioned for further reference.
And yet another very powerful and useful filter is the grep1 command. The grep command is used to search through files and print lines matching a specified pattern to standard out. The generic (non-piped) form of grep is:
grep pattern file(s)Thus we can look for specific user entries in the /etc/passwd file as follows:
$ grep flintstone /etc/passwd [Enter] fflintstone:2Ux9znoiuSpL:518:531:Fred Flintstone:/home/fflintstone:/bin/ksh wflintstone:24qza6RiyBZf:519:531:Wilma Flintstone:/home/wflintstone:/bin/kshNotice that two lines were displayed by grep, both lines matching the pattern "flintstone". Consider the following example:
$ grep fred /etc/passwd [Enter] $In this example, no results are displayed because fred does not match Fred since grep is case sensitive (unless using the -i, ignore case option). The pattern can contain any of Unix's metacharacters to more precisely define the pattern. There is also a egrep (extended grep) command (or grep -e) which extends the pattern matching capability.
When using grep with pipes, the file argument is omitted since the input data is arriving via the pipe as follows:
$ cat /etc/passwd | grep flintstone [Enter] fflintstone:2Ux9znoiuSpL:518:531:Fred Flintstone:/home/fflintstone:/bin/ksh wflintstone:24qza6RiyBZf:519:531:Wilma Flintstone:/home/wflintstone:/bin/kshWhile some search patterns using grep are straight forward, others while appearing simple are not. See an example here.
1 Although there are many explanations about what grep stands for, the name came from an ed (an early editor program) command, specifically g/regular-expression/p; where the g stands for global, the regular-expression was shortened to re, and the p stands for print. [Kernighan & Pike]
 |
 |
©2023, Mark A. Thomas. All Rights Reserved.