But what it the process we use to arrive at a solution?
One way to describe the process of problem solving might be the following:
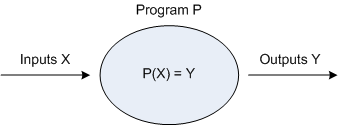
Step 2 may sound similar to step 1, but it involves a lower-level, more detailed understanding. Try to understand exactly what is required to allow the solution to be realized. Think of this process as manipulating inputs into desirable outputs. Visually, one can view this of this as follows:
where a set of inputs (X) is going to be manipulated by program P, such that this manipulation will result in desired outputs (Y). Relate this diagram to your understanding of algebraic functions. Consider also, that invalid inputs will never yield the desired outputs.
Some problems have such complexity that they cannot be solved in a single undertaking. In this case, step 3 directs us to divide the problem into pieces, such that each subdivided piece is easier to solve. If a subdivided piece still has such complexity that a solution is difficult, subdivide further until a manageable solution is found.
Once a problem is subdivided into manageable pieces (if required), each individual piece can be solved (step 4). As each piece is solved, you might consider how to tell if a particular piece's solution is correct?
Following the solution of the individual pieces, reassembly of the solved pieces can begin (step 5). Then once reassembly is complete, one can verify if the solution results match the expected results (outputs) from step 1 and 2. How does one do all of this you ask? That's what we'll look at next.
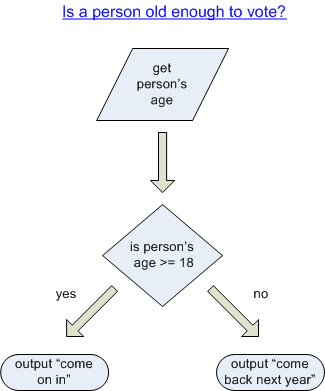
Several techniques exist for describing algorithms, but the two I wish to consider are flowcharts and more importantly (and more useful in my opinion) pseudocode. Flowcharts are graphical representations of how a problem or process flows. There are special symbols that have predefined meaning in the flowchart diagram, such as input/output symbols, decision symbols, and many more (which I am not going to mention here). If we look at a sample flowchart, representing the problem "Is a old enough to vote?" (ignoring other factors), we can observe the following flowchart:
The other technique used (more commonly in today's world) for describing algorithms is the use of pseudocode. Pseudocode is an English language-like description of the problem solution (where pseudo means false). Pseudocode is not representative of any specific proramming language, and therefore can not be used for actual programming, it is merely a solution description. Thus, sample pseudocode for the problem above might look something like:
Note that not every individuals pseudocode will look exactly the same. For example, one may use "get persons name" as above, or one may use "input persons name", but the intent should be clear in any case.
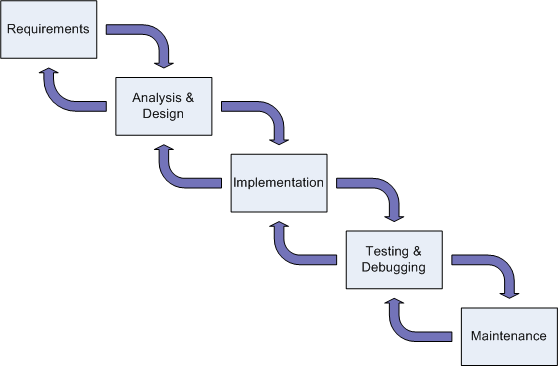
The classic waterfall model consists of five steps or phases and looks as follows:
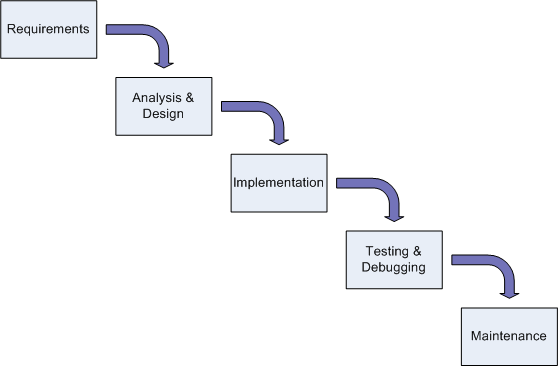
The requirements phase is where the developer (or requirements specialist) determines exactly what the user/customer wants. Any and all communication tools can be used here; for example graphics, drawings, spoken or written dialog, etc. What is really important is that the customer and the developer understand each other completely. So customers always know exactly what they want, you ask? We'll get to that later.
In the analysis & design phase, the developer (or development team) begins to digest what the customer wants and begins to devise a solution. Once it is understood what the customer wants, algorithm development can begin to map the required inputs to the desired outputs. Note that no programming has taken place yet!
In the implementation phase, coding begins based upon the algorithm(s) developed in the prior phase.
In the testing & debugging phase, implemented code is tested based upon the expected results. If errors are detected, attempts to fix them are undertaken in this phase.
In the final maintenance phase, tested and verified code is maintained as bug fixes are introduced as well as any new features added.
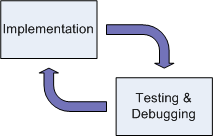
Consider the testing and debugging phase for a minute. If serious bugs, such as design flaws are discovered here, more than simple debugging fixes need to occur. Perhaps the developer needs to take a step back to a previous phase, and perform more detailed development. Should this is the case, this could be graphically represented in the model diagram as follows:
In fact, depending upon the circumstances, the development team may need to step back one or more phases, perhaps all the way to the first phase. Customers are well known to not really know what they want, or to change their minds. Should a customer change what they want (in the requirements), a return to the first step would be required. In reality, the actual model in its entirety would look as follows:
Students sometimes ask "which step is the hardest or which is easiest?" This is difficult to answer, depending upon the problem. What can certainly be stated is all steps are extremely important. Moreover, it is certainly true that a poor effort on any step will cause all downstream steps to be even more difficult to complete with desirable success. The lesson here is to spend the appropriate resources on each step, thus resulting in greater success with each successive step; thus ultimately resulting in a superior software product.
| Next Section: Intro to OO Concepts | Table of Contents |
©2007, Mark A. Thomas. All Rights Reserved.
